Các khái niệm cốt lõi cần nắm khi làm việc với Redis
Redis Core Concept
Giới thiệu
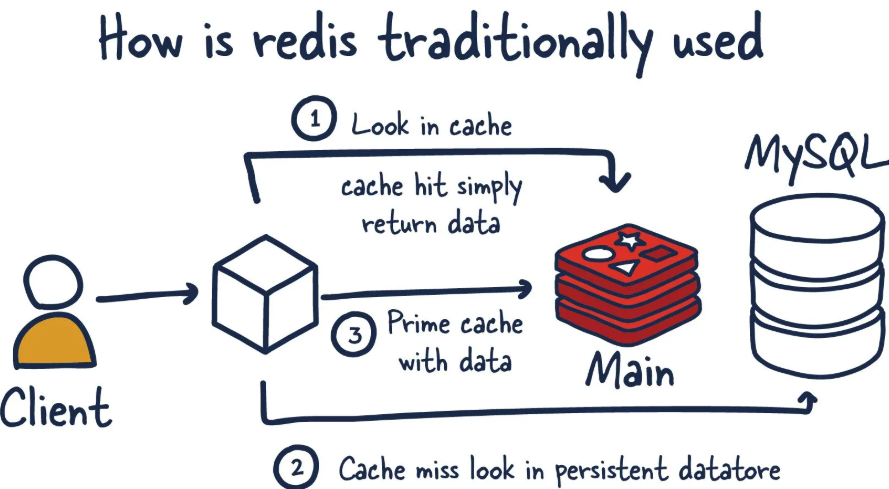
Redis đã trở thành một nền tảng trong phát triển phần mềm hiện đại, được ngưỡng mộ vì hiệu suất, tính linh hoạt và sự đơn giản của nó. Trong bài viết này, chúng ta sẽ đi sâu vào những điều cơ bản của Redis, khám phá cách thức hoạt động bên trong của nó và tìm hiểu các trường hợp sử dụng nâng cao, bao gồm việc sử dụng Bloom filters để xử lý các tập dữ liệu khổng lồ một cách hiệu quả.
Tìm Hiểu Về Cơ Sở Dữ Liệu
Trước khi đi sâu vào Redis, hãy cùng xem lại một cách ngắn gọn cơ sở dữ liệu là gì. Một cơ sở dữ liệu là một tập hợp dữ liệu được tổ chức, thường được lưu trữ và truy cập bằng điện tử. Cơ sở dữ liệu có thể lưu trữ dữ liệu trên đĩa (các cơ sở dữ liệu truyền thống như MySQL) hoặc trong bộ nhớ (các cơ sở dữ liệu như Redis).
Redis là gì?
Redis (Remote Dictionary Server) là một kho lưu trữ cấu trúc dữ liệu mã nguồn mở, trong bộ nhớ được sử dụng làm cơ sở dữ liệu, bộ nhớ đệm (cache), message broker và công cụ streaming.
- Không giống như các cơ sở dữ liệu truyền thống, Redis giữ tất cả dữ liệu của nó trong RAM, làm cho nó nhanh một cách đáng kinh ngạc.
- Nó hỗ trợ nhiều cấu trúc dữ liệu khác nhau như chuỗi (strings), danh sách (lists), tập hợp (sets), băm (hashes), tập hợp được sắp xếp (sorted sets), và nhiều hơn nữa.
- Redis là một lựa chọn ưu tiên khi các ứng dụng yêu cầu độ trễ cực thấp (ultra-low latency) và thông lượng cao (high throughput)
Tại Sao Redis Lại Nhanh?
- In-Memory Database: Tất cả các hoạt động đều xảy ra trong bộ nhớ, loại bỏ độ trễ gây ra bởi I/O của đĩa.
- Optimized Data Structures: Redis cung cấp các cấu trúc dữ liệu hiệu quả được điều chỉnh cho các hoạt động tốc độ cao.
- Single-Threaded Design: Mặc dù nghe có vẻ phản trực giác, bản chất đơn luồng của Redis tránh được chi phí quản lý và đồng bộ hóa luồng (thread management and synchronization).
Bí Mật Đơn Luồng
Redis sử dụng một vòng lặp sự kiện đơn luồng (single-threaded event loop) để xử lý các lệnh. Nghe có vẻ giới hạn, nhưng đây là lý do tại sao nó hoạt động hiệu quả:
- I/O Multiplexing: Redis sử dụng ghép kênh I/O để giám sát hàng ngàn kết nối đồng thời mà không bị chặn. Nó tận dụng các lệnh gọi hệ thống như select() hoặc epoll() để xử lý nhiều yêu cầu một cách hiệu quả.
- Minimized Latency: Bằng cách tránh tranh chấp luồng (thread contention) và các vấn đề đồng bộ hóa, Redis đảm bảo các lệnh được xử lý tuần tự và nguyên tử (sequentially and atomically).
Cách Redis Xử Lý Hàng Ngàn Kết Nối
Redis sử dụng lập trình hướng sự kiện (event-driven programming):
- Khi một client gửi yêu cầu, Redis thêm nó vào vòng lặp sự kiện.
- Sử dụng ghép kênh I/O, Redis xác định những kết nối nào đã sẵn sàng để đọc hoặc ghi.
- Nó xử lý yêu cầu, thực thi nó, và gửi phản hồi — tất cả đều nằm trong một vòng lặp đơn luồng.
Trường Hợp Sử Dụng Nâng Cao: Tìm Kiếm Một Tỷ Tên Người Dùng
Hãy tưởng tượng một kịch bản nơi bạn cần kiểm tra xem một tên người dùng có tồn tại trong cơ sở dữ liệu của một tỷ tên người dùng hay không. Các phương pháp truyền thống như truy vấn cơ sở dữ liệu quan hệ thì quá chậm. Ngay cả việc sử dụng Redis làm bộ nhớ đệm trực tiếp cũng có thể tiêu tốn một lượng đáng kể bộ nhớ.
Bloom Filters Giải Cứu
Bloom Filter là một cấu trúc dữ liệu xác suất cho bạn biết liệu một phần tử có thể tồn tại hay chắc chắn không tồn tại. Nó sử dụng:
- Một mảng bit để lưu dữ liệu
- Các hàm băm để ánh xạ dữ liệu thành các bit trong bảng
Cách thức hoạt động
- Khi thêm một tên người dùng, Bloom filter sử dụng nhiều hàm băm để đặt các bit trong mảng
- Kiểm tra sự tồn tại:
- Áp dụng các hàm băm tương tự
- Nếu tất cả các bit tương ứng được đặt thành 1, tên người dùng có thể tồn tại
- Nếu bất kỳ bit nào là 0, tên người dùng chắc chắn không tồn tại
Ưu điểm
- Hiệu quả bộ nhớ (Memory Efficiency): Một Bloom filter cho một tỷ tên người dùng với tỷ lệ lỗi 0.1% chỉ yêu cầu khoảng ~1.67GB bộ nhớ.
- Tốc độ: Tra cứu và chèn là nhanh (O(1)).
Hạn chế
- False positives: Nó có thể báo cáo không chính xác rằng một phần tử tồn tại.
- Không thể xóa